Some background
It all began as a game. The plan was to create a cipher that yields a completely different ciphertext for every change in the input, with a result as random as possible from the attacker's perspective.
The first step towards a cipher was a key derivation function. Hence the katakerm algorithm which has the basic properties of a hash function. Crafting it helped me comprehend the basic mechanism behind hashing: cascading every difference of the input everywhere on the output.
That was my eureka! moment for the cipher: even the slightest change of a single bit should yield a completely different result, i.e. it should be cascaded everywhere on the output. But unlike in hash functions, it should be done in a way that does not hinder the retrieval of the original plaintext.
After some weeks of trial and error, a couple of plans that were as doomed as the Coyote's, and some other eureka! moments, my solution evolved to this: a CBC structure with the message digest of both the plaintext and the password as initialization vector, and then just... well, just any byte-by-byte modification of the input. Even a simple XOR operation might suffice.
An unbreakable (?) block cipher mode of operation
and a sample implementation of it
The mode is surprisingly simple, though flawlessly implementing it can be very demanding:
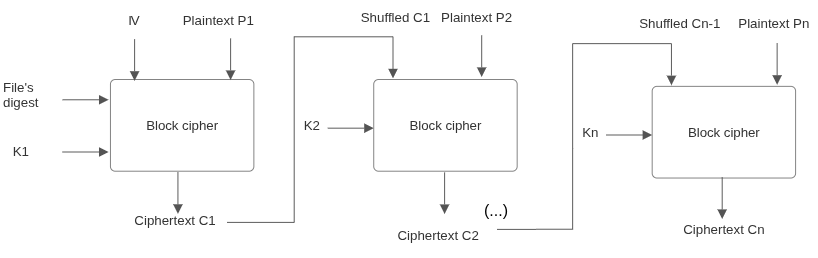
The first step of the encryption is to get the message digest (or hash, as it is often referred to) of the plaintext. It will be used as an input to the block cipher, and can then either be stored somewhere and be given by the user as input along with the password, or be chaffed (dispersed) through the ciphertext only to be winnowed (retrieved and removed) before the decryption, or even just be pasted as is in a header. No matter the approach, in a good cipher, knowing the original digest without knowing the password should be of no value.
Using the file's digest in that way makes sure that every change on the plaintext, however insignificant, is cascaded onto all the ciphertext in a chaotic manner. And no matter how many plaintexts you encrypt with the same main key, they always appear as random as if they were just digests. Many major forms of cryptanalysis are already rendered useless.
The second step is to use the digest and the key to encrypt the first block. The first block could use a pad-generator along with a regular cipher, using the key and the digest to generate a unique pad of equal length to the block (as APOCRYPTOR does). Unless there is a flaw in the underlying hash function, this pad is in practice unique for every plaintext. If the block cipher is sufficiently complex, it should suffice with no need for a pad generator for the first block.
The third step, after encrypting the first block and saving it, is getting a key- and hash-dependent permutation (shuffling) of the result, and use it as input to the block cipher -either as a simple XOR operation, or with any more complex algorithm.
One could, of course, save the shuffled ciphertext in the encrypted file, but this could weaken the algorithm: it would give an attacker knowledge of an input was used for a block. Using a key-based permutation of the ciphertext rather than the ciphertext itself, is essential to hinder attacks.
The keys used for each block may differ (e.g. n-th digest of the original key for the n-th block), but it is not necessary. The key(s) used for shuffling could be derived from the combination of the digest and the password as well, hence making the shuffling different for every input.
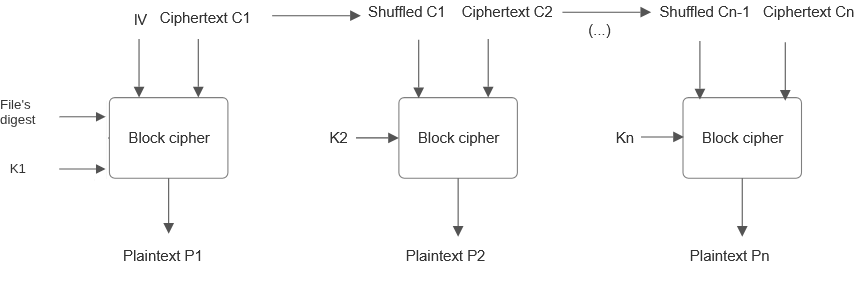
On decryption, the first step is retrieving the message digest of the original plaintext, if it was chaffed. Or just getting it from the header, or any other method one used to store it.
We then regenerate the pad of the first block, and decrypt it. The ciphertext itself is then shuffled according to K1, and used as input for the decryption of the second block. The second block would be shuffled depending on K2 and used for the decryption of the third block. The And so on.
A proper implementation of this encryption/decryption mode should yield completely different results, and random from the attackers perspective, and be unbreakable.
APOCRYPTOR: a proof of concept
APOCRYPTOR is a sample implementation of this encryption mode, used just as a proof of concept.
In this implementation, the message digest or the original plaintext is chaffed (dispersed) through the ciphertext, and winnowed (retrieved and removed from the file) right before the decryption. Katakerm is used as a hash function. Blocks of 1024 bytes are used.
We utilize the key and plaintext digest to generate a pad for the first block by using combinations of them to get some first message digests, which in turn are used to get some second message digests, and so on, until a pad of 1024 bytes is generated.
The permutation step is a simple shuffling of the 32byte subblocks of the n-th block depending on the n-th digest of the original key. The bytes of the digest are treated as integers and sorted from lowest to highest, with some special handling for repeated values. Let J the sorted array. Each block of the input has its' position changed depending on J (e.g. if the first value of J corresponds to the 4th value of the digest, the 4th block goes first). A more complex permutation algorithm is under construction.
APOCRYPTOR as of 7/2025 is crudely written, and unsuitable for production use.
No measures are taken for wiping used RAM or preventing the OS from storing temporary data, e.g. the keys in plaintext. Since the JVM cannot really prevent the OS from doing some things, APOCRYPTOR will remain a sample implementation as a proof of concept.
The purpose of APOCRYPTOR is to test and verify that even a basic implementation of this "eureka!" cipher mode, produces entirely different and apparently random ciphertexts for even the slightest change of the input or password used.
You can modify the "ENCRYPT_ME" file under /resources and/or change the password in APOCRYPTOR.java, and see the results for yourselves, in both the console, and under your /target/classes.
© George Malandrakis, 2025
Notes
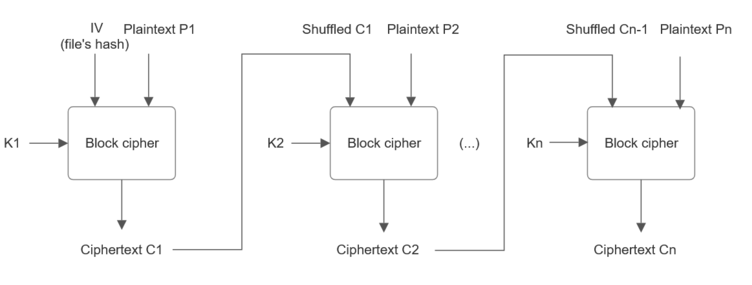
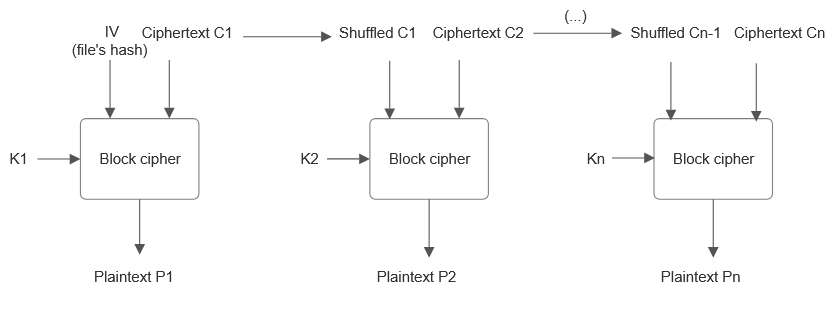
1. After initially posting the original encryption and decryption scheme, I asked experienced cryptographers on Reddit and StackExchange, and though no one implied the scheme is anyhow easy to break, all insisted that it is not completely secure. Their main objection was that Initialization Vector is not random and would encrypt a particular plaintext in the same way for a particular key -which is against modern encryption standards. Though the danger is more theoretical than practical, the mode was hardened by using a randomly generated IV like any CBC cipher, and the combination of the digest and the key.
{kind=link}
{kind=link}
2. The mode with the hardening I suggested above is, according to some Redditors, a variation of MAC-then-encrypt scheme, which some "very smart people" (I am taking this as a compliment) came up with 30 years ago, seems mostly secure, but some mathematical proofs that there still is some potential for cryptanalysis exist. I don't have the necessary knowledge or even intelligence to understand those proofs, but giving it a try seems to be a new TODO for my spare time. APOCRYPTOR-like algorithms still are (or seem) extremely tough to break, though.